

Why connection pooling is important?
To understand the importance of connection pooling we first need to understand how the application interacts with the database.
The data layer in the application requests the data source for a database connection.
The underlying driver opens a physical connection.
TCP socket is opened after physical connection establishment.
Datasource lends the physical connection to the application layer.
Using acquired connection from data source application executes the statements.
TCP socket and physical connection are closed when the connection is no longer needed.
Following the above steps for each user becomes very costly and a waste of resources.
A connection pool is a cache of database connections maintained so that connections can be reused when future requests to the database are required. It avoids overhead for establishing a TCP connection, thus cutting the amount of time a user must wait to establish a connection to the database. Another advantage for JVM applications, client-side object garbage is also reduced.
How does connection pooling work?
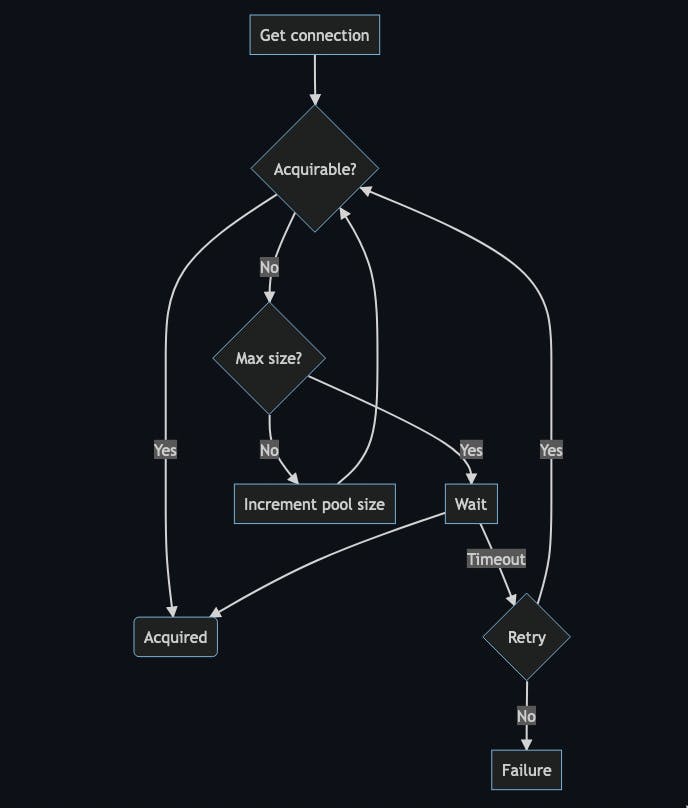
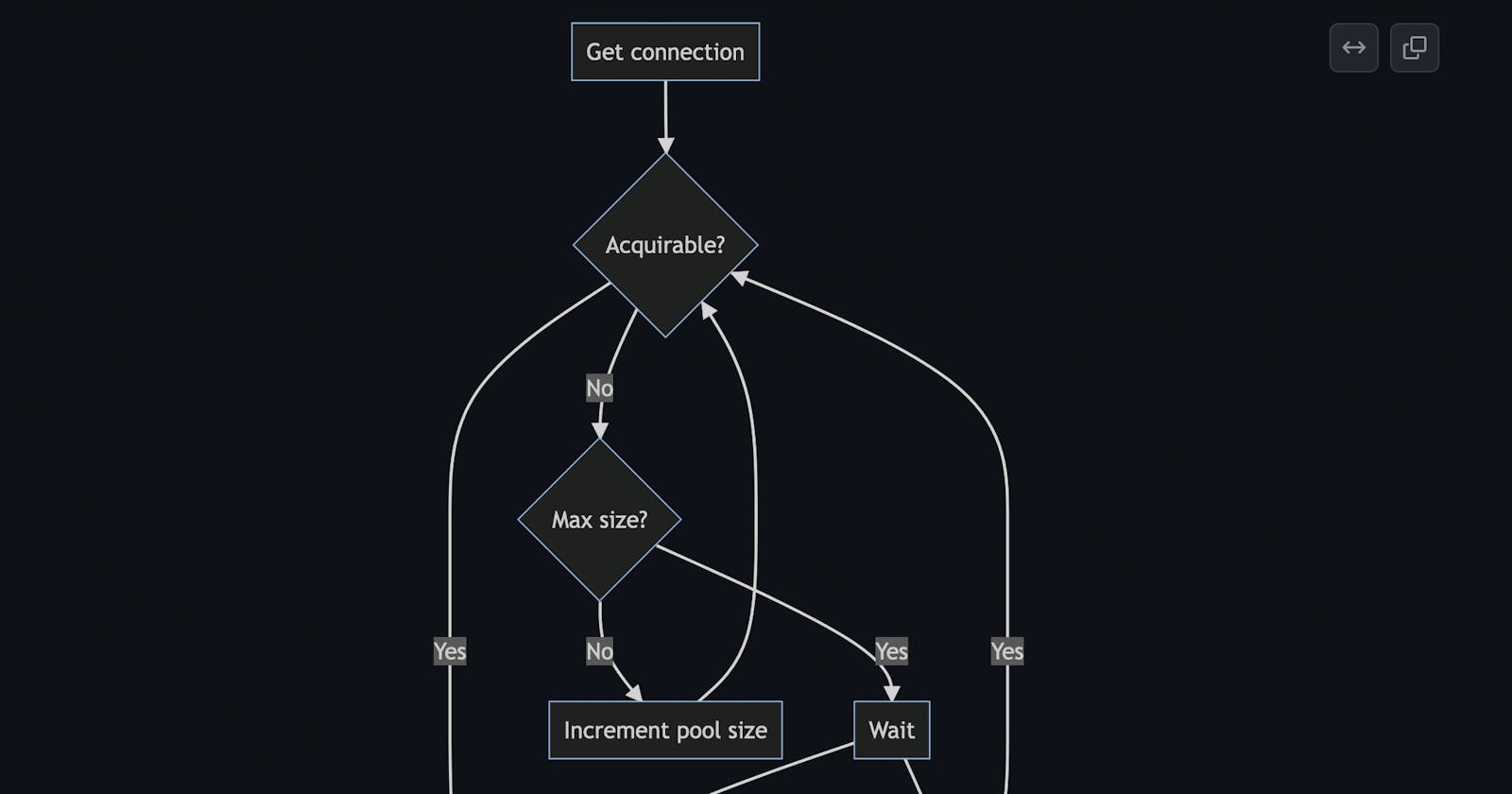
Whenever there is a request for a connection, the pool looks for unallocated connections.
The pool handles the connection to the client if it finds one.
In the case of no free connection, the pool will try to grow to its maximum allowed size.
The pool retries several times before giving up with a connection acquisition if the pool already reached its maximum size.
When the client closes the logical connection, the connection is released and returns to the pool without closing the underlying physical connection.